编辑备注:本文内容涵盖编程知识,如站长在阅读时遇到涉及法度算法公式时,建议只需体会年夜意便可,无需解读公式,重在体会PageRank算法的根基概念。
作者:张洋
很早就对 谷歌 的 PageRank 算法很感兴趣,但一直没有深究,只有个轮廓性的概念。前几天趁团队 outing 的机缘,在动车上看了一些相关的资料,连成一气,将所看的东西整理成此文。

本文首先会讨论搜索引擎的核心难题,同时讨论早期搜索引擎关于成果页面重要性评价算法的窘境,借此引出 PageRank 产生的布景。第二部分会详细讨论 PageRank 的思想来历、根本框架,并连络互联网页面拓扑布局讨论 PageRank 措置 Dead Ends 及平滑化的体例。第三部分讨论 Topic-Sensitive PageRank 算法。最后将讨论对 PageRank 的 Spam 抨击打击体例:Spam Farm 以及搜索引擎对 Spam Farm 的防御。
搜索引擎的难题
谷歌 早已成为全球最成功的互联网搜索引擎,但这个当前的搜索引擎巨无霸却不是最早的互联网搜索引擎,在 谷歌 呈现之前,曾呈现过许多通用或专业范畴搜索引擎。谷歌 最终能击败所有竞争敌手,很年夜水平上是因为它解决了困扰前辈们的最年夜难题:对搜索成果按重要性排序。而解决这个问题的算法就是 PageRank。毫不夸大的说,是 PageRank 算法成绩了 谷歌 今天的低位。要理解为什么解决这个难题如此重要,我们先来看一下搜索引擎的核心框架。
搜索引擎的核心框架
虽然搜索引擎已经成长了很多年,可是其核心却没有太年夜转变。从素质上说,搜索引擎是一个资料检索系统,搜索引擎拥有一个资料库(具体到这里就是互联网页面),用户提交一个检索条件(例如关头词),搜索引擎返回适合查询条件的资料列表。理论上检索条件可以很是复杂,为了简单起见,我们无妨设检索条件是一至多个以空格分隔的词,而其表达的语义是同时含有这些词的资料(等价于布尔代数的逻辑与)。例如,提交"张洋博客",意思就是"给我既含有‘张洋’又含有‘博客’词语的页面",以下是 谷歌 对这条关头词的搜索成果:
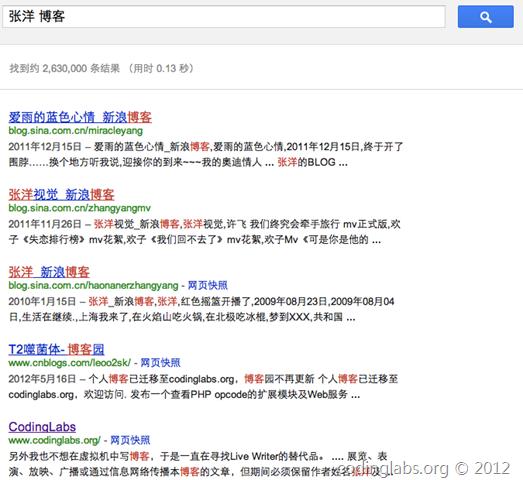
可以看到我的博客呈现在第五条,而第四条是我之前在博客园的博客。
当然,实际上现在的搜索引擎都是有分词机制的,例如如果以"张洋的博客"为关头词,搜索引擎会自动将其分化为"张洋的博客"三个词,而"的"作为停止词(Stop Word)会被过滤失落。关于分词及词权评价算法(如 TF-IDF 算法)是一个很年夜的话题,这里就不展开讨论了,为了简单此处可以将搜索引擎想象为一个只会机械匹配词语的检索系统。
这样看来,成立一个搜索引擎的核心问题就是两个:1、成立资料库;2、成立一种数据布局,可以按照关头词找到含有这个词的页面。
第一个问题一般是通过一种叫爬虫(Spider)的特殊法度实现的(当然,专业范畴搜索引擎例如某个学术会议的论文检索系统可能直接从数据库成立资料库),简单来讲,爬虫就是从一个页面解缆(例如新浪首页),通过 HTTP 协议通信获得这个页面的所有内容,把这个页面 url 和内容记实下来(记实到资料库),然后阐发页面中的链接,再去别离获得这些链接链向页面的内容,记实到资料库后再阐发这个页面的链接……重复这个过程,便可以将整个互联网的页面全部获得下来(当然这是抱负情况,要求整个 Web 是一个强连通(Strongly Connected),并且所有页面的 robots 协议允许爬虫抓取页面,为了简单,我们仍然假定 Web 是一个强连通图,且不斟酌 robots 协议)。抽象来看,可以将资料库看作一个巨年夜的 key-value 布局,key 是页面 url,value是页面内容。
第二个问题是通过一种叫倒排索引(inverted index)的数据布局实现的,抽象来讲倒排索引也是一组 key-value 布局,key 是关头词,value 是一个页面编号调集(假定资料库中每个页面有唯一编号),暗示这些页面含有这个关头词。本文不详细讨论倒排索引的成立体例。
有了上面的阐发,便可以扼要说明搜索引擎的核心动作了:搜索引擎获得"张洋博客"查询条件,将其分为"张洋"和"博客"两个词。然后别离从倒排索引中找到"张洋"所对应的调集,假定是{1, 3, 6, 8, 11, 15};"博客"对应的调集是{1, 6, 10, 11, 12, 17, 20, 22},将两个调集做走运算(intersection),成果是{1, 6, 11}。最后,从资料库中找出1、6、11对应的页面返回给用户便可以了。