前面的一篇文章介绍了可以用来评估KPI的数据上下文——质量节制图,通常我们会用KPI来权衡一些内容的质量、流量的质量,以及拜候的质量等,我们常常按照KPI指标直接排序,并认为排在前几名的就是优质的内容,但其实这种体例其实不是对所有的KPI都有效。举个最简单的例子:转化率Conversion Rate是很多网站的KPI指标,一般我们会让为Conversion Rate越高则渠道质量越好,或内容质量越高,但有一种情况,如果网站内容普遍的转化率为10%,但有一个内容的拜候次数一共2次,其中有一次实现了成功的转化,那该内容的转化率就是50%,是不是很"高"?是不是真的有这么高?
所以我们在阐发关头指标的转变趋势,节制KPI的质量的时候,还需要注意一个问题,那就是如何运用KPI进行有效的评价。
其实谷歌 Analytics已经给了我们谜底,在前段时间推出了Weighted Sort(赋权排序)的功能,Avinash Kaushik先生在先前的博文——End of Dumb Tables in Web Analytics Tools! Hello: Weighted Sort对这个功能做过介绍,因为近段时间需要用到这个功能,但我的数据其实不在GA上,所以我必须自己设计一套给关头指标赋权的体系,以发现到底这些KPI值可以达到多少预期,这里来分享下我的应用实例。
KPI期望值公式
仍是以转化率Conversion Rate为例,电子商务中每个商品的转化率应该是:采办该商品成功的数量/该商品被阅读的次数,所以从统计学的角度来看,当商品的阅读次数(无妨叫做基数,数学上的调集元素个数或统计学上的样本总数)这个基数越年夜时,转化率CR的置信度也就越高,同样是10%的转化率,阅读次数为1000的商品显然要比阅读次数只有100的商品在转化率这个数值上的可托度要高。
按照上面的结论,我们需要按照每个商品转化率的真实值(Actual Value),权衡它的可托度,进而计较取得该商品转化率的期望值(Excepted Value),而这里的可托度就是真实值可以取得的权重,比如60%,那么还有个问题,既然是加权和,别的的40%的权重应该由什么来中和呢?参考GA中Weighted Sort的计较公式,用的是均值,也就是所有转化率的平均,很是不错的idea,于是我们可以取得以下公式了:
期望值(Excepted Value)=权重(Weight)×真实值(Actual Value)+(1-权重)×均值(Average Value)
我们看看哪些数据我们现在便可以拿到,权重显然还不可,真实值应该已经统计取得了,均值?既然有了所有的真实值,那么均值就是一个取平均的简单计较了。好的,那下面就说说我是如何来确定这个权重的。
权重的确定
先看看权重需要适合哪些原则,应该表示为怎样的一个特征。显然,权重的取值范围应该在[0,1],也就是0到100%之间;别的,权重跟基数应该是正相关的,也就是基数越年夜,权重应该越年夜。如果你看过我之前的文章——数据的标准化,是不是已经想到了什么?是的,里面有几个公式可以直接用,简单地说,就是将基数进行归一化措置。
KPI的基数一般都是自然数,比如转化率的阅读次数、Bounce Rate的拜候数,人均消费的用户数等,所以归正切函数atan不适用,min-max和log函数都适用,可以用散点图简单看一下别离用这两种体例归一化之后权重和基数的转变关系:
Min-max
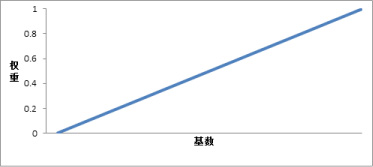
Min-max是直线的正相关,也就是权重和基数同比例地转变,转变速度一直。
Log函数
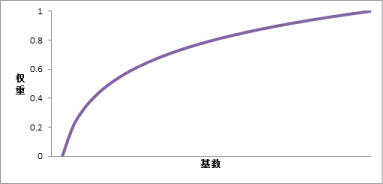
Log函数是对数曲线的正相关,也就是权重的转变速度要比基数来得快。
按照这两个别例的特征,我选择了log函数作为权重的计较函数,因为它更适合基数和可托度之间的关系。
应用实例
既然KPI期望值的计较公式,及公式所有需要的数据都已经可以取得了,那么我们就来看看,KPI的基数是如何影响KPI的期望值的:
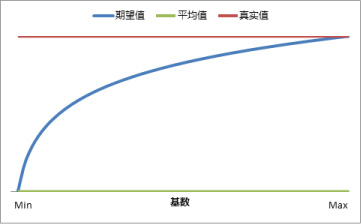
即基数越年夜,期望值越接近真实值,反之,则越接近平均值。算法和公式确定之后,我们便可以将其应用到实际的案例傍边去了,这里以网站的转化率CR为例,看看这个KPI期望值的算法是不是有效的。