学习搜索引擎优化的人常常在网上看到一句话:搜索引擎蜘蛛跟阅读器差不多,都是抓取页面。那么到底哪些一样哪些不一样?Ethan就通过阅读器帮忙年夜家理解搜索引擎蜘蛛怎样抓取页面。
首先看一张图,是用firebug(firefox阅读器的一个著名插件)记实下来的阅读器抓取我网站的情况。
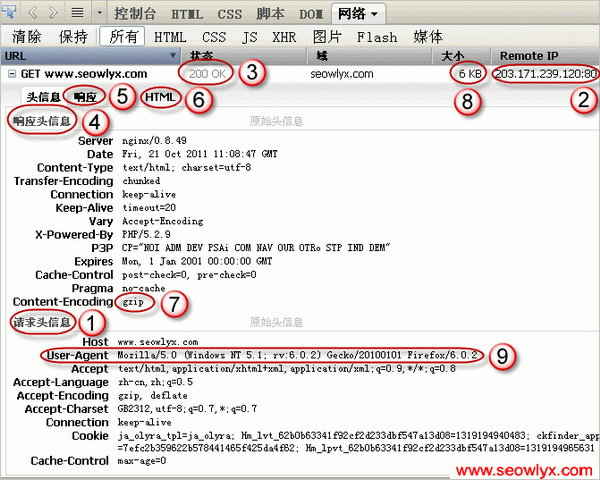
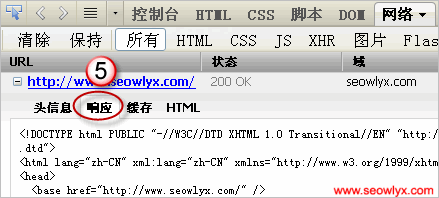
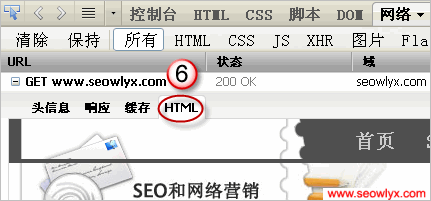
针对图中标识,Ethan诠释如下。
1.http协议起头,HTTP协议是典型的请求/响应模式,客户端请求办事器,然后客户端和办事器成立姑且通道,然后办事器返回响应。这里阅读器是一种客户端法度,搜索引擎蜘蛛也是一种客户端法度。客户端向办事器发送请求行,然后是请求头信息。图中左上角有"GET ***",反应了请求行的内容,真正的请求行是下面这行,firebug没有明示:
"GET / HTTP/1.1"
这行的格局是:
请求体例(get、post等)+一个空格+请求的URL(这里"/"暗示首页)+一个空格+http协议版本(现在通常是HTTP/1.1,就是http协议1.1版)
记住这个格局,我们在办事器日志里还会看到这种格局的数据。
请求行后面紧随着请求头信息,其中第一行是host字段,指明了办事器是***,这是个域名,通过DNS域名解析,酿成ip地址,也就是办事器的物理地址。
2.ip地址,后面冒号加80,表白拜候的是办事器的80端口。办事器一直处于待命状态,侦听80端口,一旦发现有适合HTTP协议的头信息发过来,就和客户端成立一个姑且通道,然掉队行内部措置,并把成果通过姑且通道返回给客户端。在这个措置的同时,办事器还可以接管其它HTTP请求。
3.客户端起头领受响应信息,最先过来的是状态行,真正的状态行是下面这行,firebug没有明示:
"HTTP/1.1 200 OK"
这里的200就是状态码,暗示网页顺利打开。
4.然后客户端收到响应头信息。
5.最后客户端收到响应主体,也就是html代码。
6.注意这里阅读器和搜索引擎蜘蛛不合,阅读器会对html代码进行措置,显现出我们看得懂的网页;搜索引擎蜘蛛则只负责抓取,把html代码存在数据库里,自己快速去抓取下一个网页。搜索引擎在各地都有蜘蛛办事器,每个办事器同时放出很多蜘蛛,日夜不断地抓取网页。
7.注意响应头信息里有一行gzip,暗示html代码颠末了gzip压缩。不过没有关系,阅读器和搜索引擎蜘蛛都可以解压缩gzip文件。
8.html代码的年夜小,如果不压缩,远不止6k。搜索引擎对网页文件年夜小有个上限,一种说法是128k(未压缩),逾越128k的内容不再抓取。
9.注意User-Agent,正是请求头信息里的这个字段,奉告办事器抓取网页的是阅读器仍是搜索引擎蜘蛛。有的办事器为了不让百度蜘蛛抓取,会封禁百度蜘蛛的User-Agent,拜见百度站长俱乐部发布的百度Spider User-Agent字段更新通知。
本文为搜索引擎优化wlyx的站长梁波(Ethan)原创,转载请注明,谢谢!