上一讲我们介绍了帝国cms收集根基流程,那么我们这一讲介绍帝国cms如何收集内容分页。很多的同学在收集过程中,列表页和内容页都能可以很好地设定正则,但往往失败在内容分页正则上,主要是对内容分页正则不体会。帝国的内容分页形式有两种:(1)全部列出式(2)上下页导航式,可是这两种内容分页形式有什么区别,收集内容分页时该用哪种,官方说得比较模糊,对此有些同学感应很头年夜,好的,我们先看下例子:
一、全部列出式
全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列出来了。
1、我们以"中华网内容分页(http://auto.china/dongtai/yejie/11012724/20120309/17081442.html)"为例:
![]()
可以看到这条新闻总共有3条分页。
2、查看源代码:

这一页里除已经收集到的第1条分页外,还包含了第2条和第3条分页,所有的分页都列出来了。
3、取得 分页区域正则([!--smallpageallzz--]):
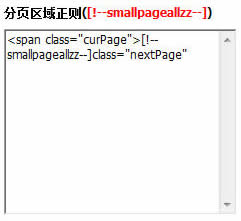
4、取得 分页链接正则([!--pageallzz--]):
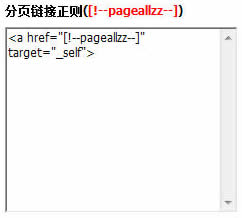
2、上下页导航式
上下页导航式是分页收集的难点,他需要所有页面都适合分页正则才行,在不熟悉的情况下,我们可以用第1页和第2页的代码来进行对比阐发然后确定分页正则。
1、我们以下网站的内容分页为例:
![]()
可以看到这条新闻总共有20条分页。
2、查看源代码:

这一页里除已经收集到的第1条分页外,还包含了第2,第3,第4,第5,第6,第7,第8,第20条分页,可是第9到第19条分页并没有列出来,这时候我们拿用第1页和第2页的代码来进行对比阐发,来确定分页正则:
(1)第1页代码:

(2)第2页代码:

从这两幅图片可以看到他们有着相同的"分页区域起头代码","分页链接"格局,"分页区域结束代码",那么便可以确定"分页区域正则","分页链接正则"。
3、取得 分页区域正则([!--smallpageallzz--]):

4、取得 分页链接正则([!--pageallzz--]):

5、为了便利教程显示,newstext我收集了题目而不是收集内容,预览成果:

注意事项:
第一、在第一页的页面HTML代码里,内容分页链接全部列出来的情况下我们使用"全部列出式"。在第一页的页面HTML代码里,内容分页链接没有全部列出来的情况下我们使用"上下页导航式"。
第2、用全部列出式时,收集法则正确可是莫名其妙的呈现重复的分页,这时可以操纵替换法把它过滤失落(下一讲我们再说)。
第三、用上下页导航式时,总是采到第1页,其他页连个影子都没有见过,这是因为分页区域正则([!--smallpagezz--])截取毛病。