那么这个问题怎么解决呢?
对跨语言,我们自然而然想到的一种体例就是:翻译。我们可以通过翻译的体例把一个语言的词语映射到另外一语言上,从而让query和文档处于同一个特征空间中,然后再操纵单语下的检索模型进行检索和排序,这样便可以实现跨语言检索了。
Query翻译——把query翻译到文档的语言下,然后用这些翻译后的query在文档中进行检索。对query中的词语,我们可以选择若干可能的翻译,用于扩年夜召回。这可以看作是一种query扩大。
文档翻译——把文档翻译到query的语言下,然后用原有query对翻译的文档进行检索。文档的翻译一般是在线下进行的。一篇源语言的文档通过自动的翻译(如机械翻译)变换成一篇目标语言下的文档。
这两种体例都是可以达到跨语言检索目的的,我们在实践中应该采取哪种体例呢?下面我们阐发一下这两种体例的优劣:

从上述优劣比较中我们可以看出,文档翻译虽然可能提供更准确的翻译,但它需要更多的线下措置时间,需要更多的存储空间,实用性较差。鉴于此,无论是学术界仍是工业界,一般采取的都是Query翻译的体例。
Query翻译体例的最年夜缺点就是由于词语翻译的毛病致使检索毛病。那么我们有没有体例客服这个问题呢?对自动而又切确的翻译,我们很容易会想到机械翻译。不过,如果直接使用机械翻译的成果,效果其实不克不及达到我们的预期。这是因为,首先,机械翻译和跨语言信息检索的目标是不一样的。机械翻译是为了让翻译出的文字更可读,因而会在调剂语序上下很多工夫,可是跨语言检索不需要语序,它只需要正确翻译的词语呈现便可。在机械翻译中一些无意义的毗连词(比如"there is")是重要的,可是在跨语言检索中我们完全不需要它们。其次,机械翻译的目标是取得一个最可能的翻译成果,而在跨语言检索中,我们需要保存多种翻译的成果,来提高召回。在这里,也许你会想到,我们也可以把机械翻译的成果作为根本进行同义词扩大,这样不是便可以了么?这样做其实是有很年夜风险的:如果机械翻译把某个词翻错了,那么在此之上的所有扩大城市对检索成果造成卑劣的影响。
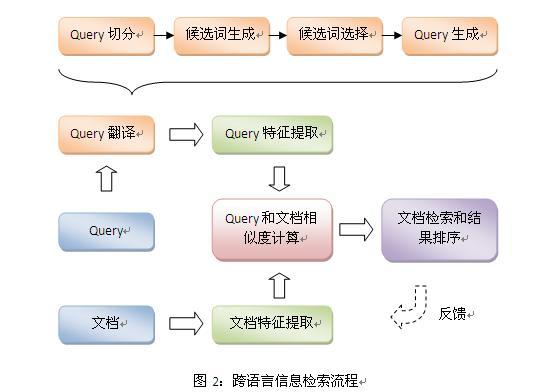
Query翻译的一般做法是这样的(如图2所示):对一个query,首先我们对它进行切分,取得一个个词语。在切分的成果中,我们把其中的无意义词语(如"的"、"吗"等)都过滤失落。对剩下的每一个有意义的词语,我们取得若干翻译候选词。然后在这些候选词语中,我们通过某种机制选择其中的一部分来生成跨语言检索的新query。举个例子:
比如有个英文的query:
"building information super highway"
我们要用它来检索中文的文档。我们可以通过翻译字典找到每个英文单词的中文候选词:
"building" -》 "建筑 / 成立"
"information" -》 "信息 / 消息 / 知识"
"super" -》 "上等的 / 超等的 / 特年夜的"
"highway" -》 "公路 / 年夜道 / 直接的途径"
英文query的原意是希望体会高速公路四周的房屋信息。按照这个需求,我们可以发现,在这些候选词里有些必须删除,比如building的翻译"成立",因为它明显不适合query的原意;有些是可以保存的,比如highway的翻译"公路"和"年夜道"。而我们的核心目标就是通过一定的体例把不公道的翻译删除,然后将公道的翻译用于检索。
在这里我们介绍一种基于词共现的体例。
比如"building"和"information"这两个词,我们首先把它们的翻译组合写出来,取得6种可能翻译:
(建筑 信息),(建筑 消息),(建筑 知识),(成立 信息),(成立 消息),(成立 知识)
在这些组合中,有些我们一眼便可以看出它是适合检索需求的,比如(建筑 信息),有些则必定不是,如(成立 消息)。那么如何让法度自动判断呢?其实很简单,我们只需要看看这些组合在中文文档中配合呈现的次数便可。正确的翻译组合在文档中呈现的频率往往较高,而毛病的翻译组合则不常呈现。这样,我们通过中文文档中词语的自然散布,便可以为翻译组合打分,把毛病的翻译组合剔除失落。