对robots.txt文件对网站的作用年夜家都知道,可是通过不雅察发现,有些朋友对robots.txt文件的法则仍是有一定的误区。
比如有很多人这样写:
User-agent: *
Allow: /
Disallow: /mulu/
不知道年夜家有没有看出来,这个法则其实是不起作用的,第一句Allow: / 指的是允许蜘蛛爬行所有内容,第二句Disallow: /mulu/指的是制止/mulu/下面的所有内容。
概况上看这个法则想达到的目的是:允许蜘蛛爬行除/mulu/之外的网站所有页面。
可是搜索引擎蜘蛛执行的法则是从上到下,这样会造成第二句命令失效。
正确的法则应该是:
User-agent: *
Disallow: /mulu/
Allow: /
也就是先执行制止命令,再执行允许命令,这样就不会失效了。
别的对百度蜘蛛来讲,还有一个容易犯的毛病,那就是Disallow命令和Allow命令之后要以斜杠/开首,所以有些人这样写:Disallow: *.html 这样对百度蜘蛛来讲是毛病的,应该写成:Disallow: /*.html 。
有时候我们写这些法则可能会有一些没有注意到的问题,现在可以通过百度站长东西(zhanzhang.百度)和谷歌站长东西来测试。
相对来讲百度站长东西robots东西相对简陋一些:
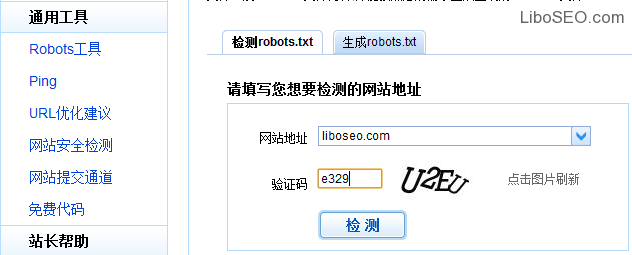

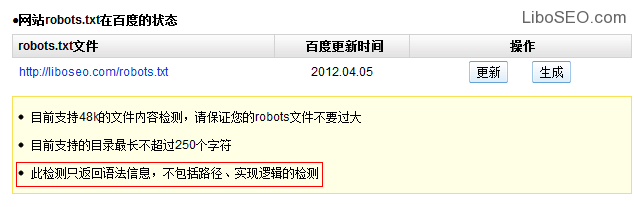
百度Robots东西只能检测每一行命令是否适合语律例则,可是不检测实际效果和抓取逻辑法则。
相对来讲谷歌的Robots东西好用很多,如图:

在谷歌站长东西里的名称是抓取东西的权限,并述说谷歌抓取网站页面的时候被阻挡了多少个网址。
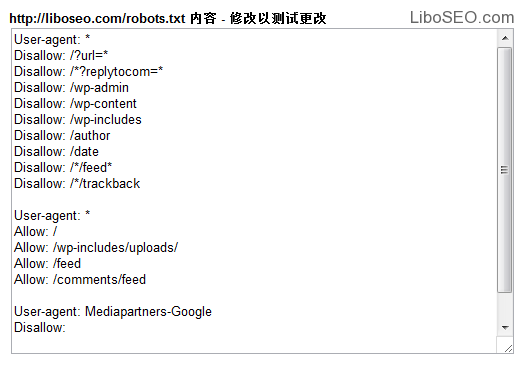
还可以在线测试Robots修改后的效果,当然这里的修改只是测试用,如果没有问题了,可以生成robots.txt文件,或把命令代码复制到robots.txt文本文档中,上传到网站根目录。
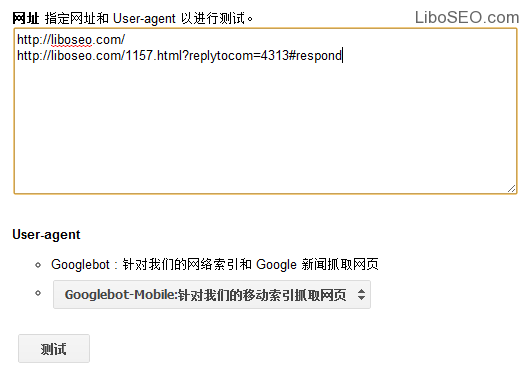
谷歌的测试跟百度有很年夜的区别,它可让你输入某一个或某些网址,测试谷歌蜘蛛是否抓取这些网址。
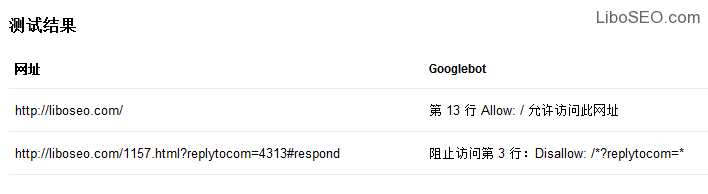
测试成果是这些网址被谷歌蜘蛛抓取的情况,这个测试对Robots文件对某些特定url的法则是否有效。
而两个东西连络起来当然更好了,这下应该完全明白robots应该怎么写了吧。
转载请注明来自逍遥博客,本文地址:http://libo搜索引擎优化/1170.html,转载请注明出处和链接!
(责任编辑:sunsun)